字典树是一棵多叉树,如英文字母的字典树是 26 叉树,数字的字典树是 10 叉树。
字典树是很多其他算法和数据结构的基础,如回文数、AC自动机、后缀自动机等,都是建立在字典树上的。
字典树的构造
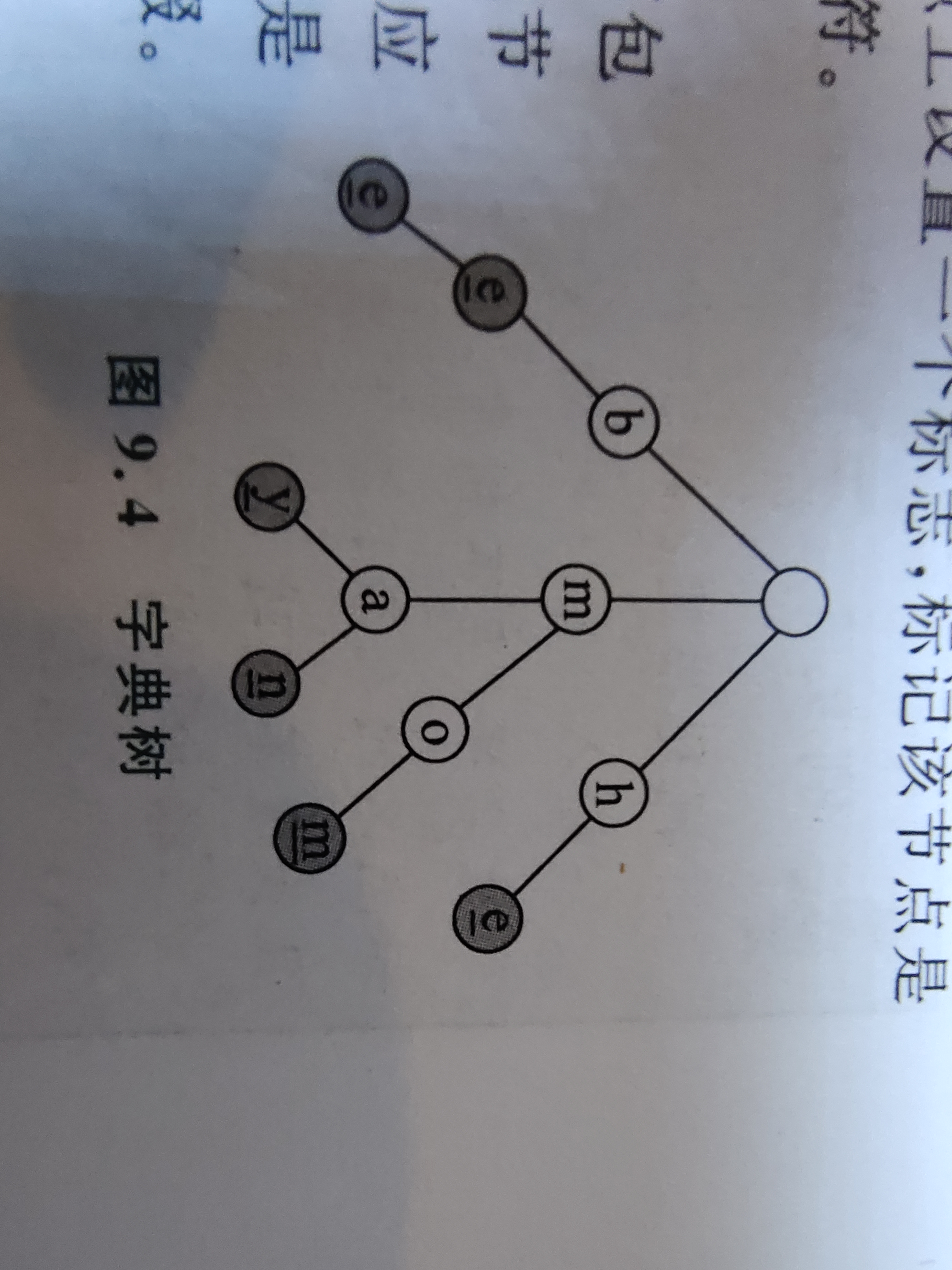
这是书上的一个字典树,所包含的单词有 be, bee, may, man, mom, he 。
多个单词存储时共用相同的前缀(Prefix)。为区分一条链上的不同字符,可以在节点上设置一个标志,标记该节点是否是一个单词的末尾,比如图中的带下划线的阴影字符。这棵字典树用 12 个节点存储了 7 个单词,共 16 个字符。
从图上可以归纳出字典树的基本性质:
- 根节点不包含字符,除根节点外的每个子节点都包含一个字符;
- 从根节点到某一个节点,路径上经过的字符连接起来,为该节点对应的字符串;
- 一个完整的单词并不是存储在某个节点上,而是存储在一条链上;
- 一个节点的所有子节点都有相同的前缀。
字典树的时间复杂度很好,但是空间复杂度比较差。
插入和查找一个单词的复杂度为 $O(m)$ ,其中 $m$ 为待插入/查询的字符串长度,与整棵树的大小无关。由于一般情况下 $m$ 都很小,所以可以认为复杂度为 $O(1)$ 。
每个子节点都要设置 $\mathrm{SIZE}$ 个子节点,而其中大多数都不会被用到,导致空间浪费。
字典树是是一种空间换时间的数据结构,所有基于字典树的数据结构和算法都有这个特征。
字典树有以下常见的应用:
- 字符串检索。检索、查询功能是字典树的基本功能。
- 词频统计。统计一个单词出现的次数。
- 字典序排序。插入时,在树的平级按照字母表的顺序插入。字典树建好后,用先序遍历,就得到了字典序的排序。
- 前缀匹配。字典树是按照公共前缀来建树的,所以很适合搜索提示符。字典树常用于处理具有相同前缀的字符串问题。
例题 洛谷2580 于是他错误的点名开始了
这之后校长任命你为特派探员,每天记录他的点名。校长会提供化学竞赛学生的人数和名单,而你需要告诉校长他有没有点错名。(为什么不直接不让他玩炉石。)
输入:
第一行一个整数 $n$,表示班上人数。
接下来 $n$ 行,每行一个字符串表示其名字(互不相同,且只含小写字母,长度不超过 $50$)。
第 $n+2$ 行一个整数 $m$,表示教练报的名字个数。
接下来 $m$ 行,每行一个字符串表示教练报的名字(只含小写字母,且长度不超过 $50$)。
输出:
对于每个教练报的名字,输出一行。
如果该名字正确且是第一次出现,输出 OK,如果该名字错误,输出 WRONG,如果该名字正确但不是第一次出现,输出 REPEAT。
思路
首先显然可以用 STL 中的 map 来解决。
当然了,这还是一个字典树的模板题。
下面直接给出实现代码,说明见注释。
代码 (STL map)
#include<bits/stdc++.h>
#define N 10010
using namespace std;
inline int read() {
int w=1,x=0;
char ch=0;
while(ch<'0'||ch>'9') {if(ch=='-') w=-1;ch=getchar();}
while(ch>='0'&&ch<='9') x=x*10+ch-'0',ch=getchar();
return w*x;
}
int n,m;
map<string,int> cnt;
int main() {
n=read();
for(int i=1;i<=n;i++) {
string nm;
cin>>nm;
cnt[nm]++;
}
m=read();
for(int i=1;i<=m;i++) {
string nm;
cin>>nm;
if(!cnt[nm]) printf("WRONG\n");
else if(cnt[nm]==1) {
printf("OK\n");
cnt[nm]++;
}
else printf("REPEAT\n");
}
system("pause");
return 0;
}代码 (字典树)
#include<bits/stdc++.h>
#define N 55
#define M 500010
using namespace std;
inline int read() {
int w=1,x=0;
char ch=0;
while(ch<'0'||ch>'9') {if(ch=='-') w=-1;ch=getchar();}
while(ch>='0'&&ch<='9') x=x*10+ch-'0',ch=getchar();
return w*x;
}
int n,m;
char s[N];
int tot=0;
struct Trie{
bool rpt,v;
int son[26],num;
}t[M];
void Insert(char *s) {
int now=0;
for(int i=0;s[i];i++) {
int ch=s[i]-'a';
if(!t[now].son[ch]) t[now].son[ch]=++tot;
now=t[now].son[ch];
t[now].num++;
}
t[now].v=true;
}
int Find(char *s) {
int now=0;
for(int i=0;s[i];i++) {
int ch=s[i]-'a';
if(!t[now].son[ch]) return 3;
now=t[now].son[ch];
}
if(t[now].num==0||!t[now].v) return 3;
if(!t[now].rpt) {
t[now].rpt=true;
return 1;
}
return 2;
}
void solve() {
scanf("%d",&n);
for(int i=1;i<=n;i++) {
scanf("%s",&s);
Insert(s);
}
scanf("%d",&m);
while(m--) {
scanf("%s",&s);
int res=Find(s);
if(res==1) printf("OK\n");
else if(res==2) printf("REPEAT\n");
else printf("WRONG\n");
}
}
int main() {
solve();
return 0;
}书上有一点有些问题。
应当再定义一个变量来记录当前节点是否是一个单词的末尾,否则就会被这样的数据给 hack ,如单词为 acm ,而点名为 ac 。
参考资料
《算法竞赛》罗勇军

